PERIA: Perceive, Reason, Imagine, Act via Holistic Language and Vision Planning for Manipulation
Abstract
Long-horizon manipulation tasks with general instructions often implicitly encapsulate multiple sub-tasks, posing significant challenges in instruction following. While language planning is a common approach to decompose general instructions into stepwise sub-instructions, text-only guidance may lack expressiveness and lead to potential ambiguity. Considering that humans often imagine and visualize sub-instructions reasoning out before acting, the imagined subgoal images can provide more intuitive guidance and enhance the reliability of decomposition. Inspired by this, we propose PERIA(PErceive, Reason, Imagine, Act), a novel framework that integrates holistic language planning and vision planning for long-horizon manipulation tasks with complex instructions, leveraging both logical and intuitive aspects of task decomposition. Specifically, we first perform a lightweight multimodal alignment on the encoding side to empower the MLLM to perceive visual details and language instructions. The MLLM is then jointly instruction-tuned with a pretrained image-editing model to unlock capabilities of simultaneous reasoning of language instructions and generation of imagined subgoals. Furthermore, we introduce a consistency alignment loss to encourage coherent subgoal images and align with their corresponding instructions, mitigating potential hallucinations and semantic conflicts between the two planning manners. Comprehensive evaluations across three task domains demonstrate that PERIA, benefiting from holistic language and vision planning, significantly outperforms competitive baselines in both instruction following accuracy and task success rate on complex manipulation tasks.
Illustrative Overview of PERIA

The overview of pipeline for PERIA(Perceive, Reason, Imagine, Act). Inspired by the human cognitive process of following complex instructions, which involves perceiving environment and tasks, reasoning the required language plans, and imagining the intermediate subgoal images before acting.
Language planning focuses on how to act and the sub-instructions outline the necessary procedural action process of the task completion, emphasizing the temporal dependencies and causal relationships between decomposed stepwise sub-instructions. On the other hand, vision planning concentrates on what to act towards and intuitive and grounded subgoal images with rich spatial and contextual information can enable robot agents to more easily understand what intermediate landmarks and visual anchors should achieve towards task completion. From a cognitive perspective, humans rely on a symbiotic operation of the brain’s hemispheres, with the left primarily associated with logical language-based reasoning, and the right is linked to intuitive visual-based imagining. For humans, language planning and vision planning are often intertwined and performed simultaneously, involving either imagining the desired intermediate goals and then reasoning about the required plans to achieve them, or first reasoning out necessary stepwise plans and then imagining corresponding resulting images. Inspired by this, a natural question arises: Can we develop a framework that emulates this cognitive synergy by simultaneously performing language planning and vision planning for robotic manipulation tasks involving complex instructions just like humans?
Two-phase Training Pipeline
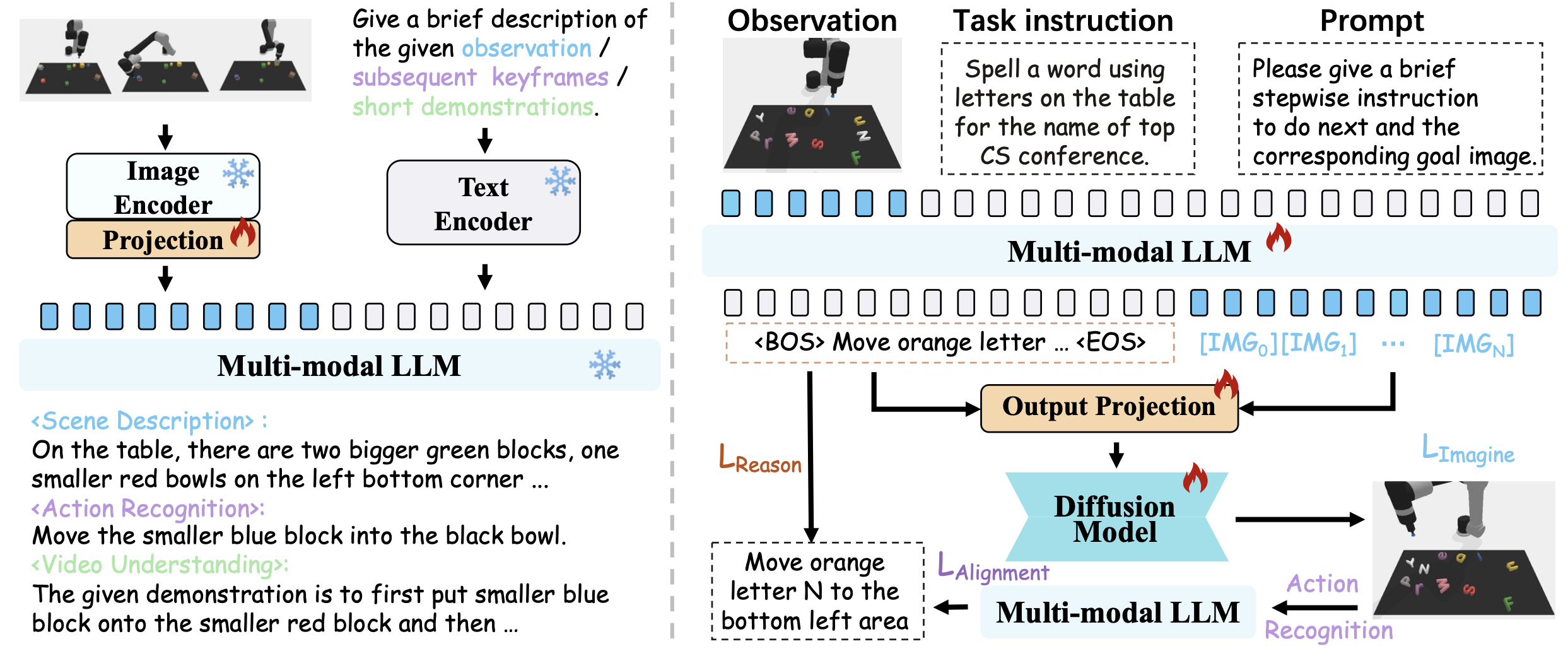
The overview of training framework for PERIA. PERIA first learns to align the vision and language on encoding side of MLLM for perceiving. Then PERIA performs instruction tuning to MLLM jointly with diffusion model in an end-to-end manner to unlock the reasoning and generation ability for holistic language planning and vision planning.
By leveraging MLLM and diffusion-based image editing models, PERIA enables holistic language planning and vision planning for stepwise language instructions and visual subgoal images, serving as language milestones and visual anchors to guide action execution in long-horizon tasks. We first introduce the lightweight alignment of language and vision modalities on the encoding side of the MLLM to achieve precise Perceive ability. We then perform instruction tuning on the MLLM to enable Reason for language planning and jointly train with a diffusion model to Imagine coherent subgoal images aligned with corresponding instructions. Moreover, we leverage an explicit alignment between instructions and images to achieve a synergistic effect between language and vision.
Details of Training
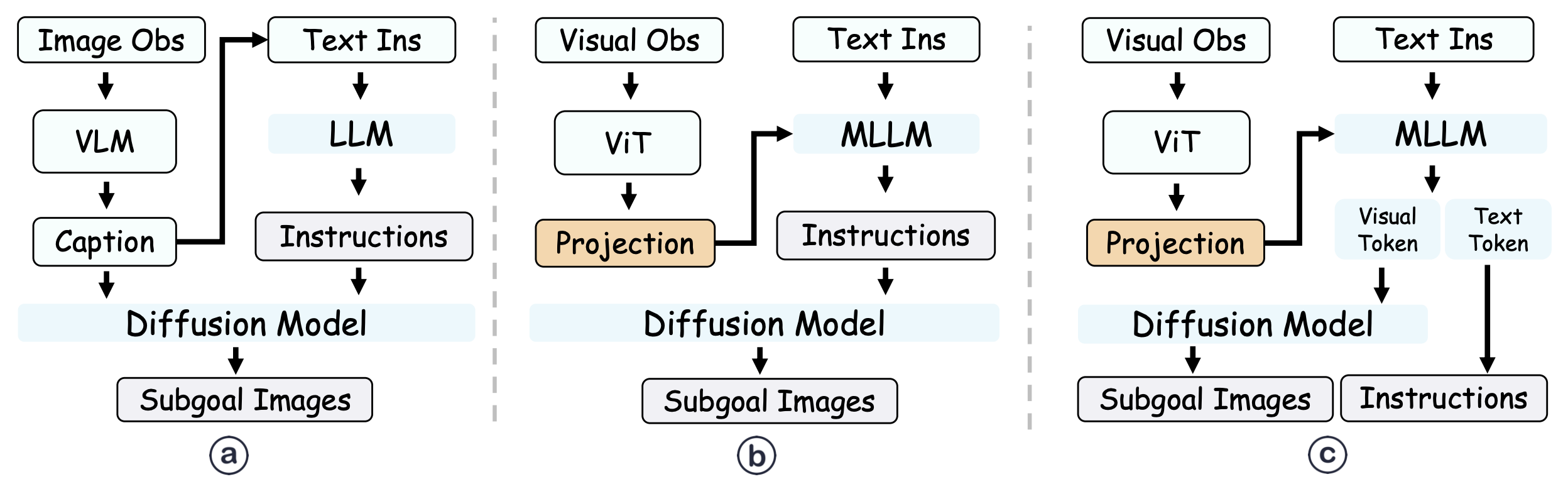
Three pipelines of MLLM for generation images. PERIA leverage visual tokens extracted from the MLLM during language planning serve as more expressive guidance for subgoal imagination compared to captions or decomposed instructions in language only.
While a natural approach would be to directly use the text instructions or captions as prompts for the image editing model, relying solely on decoded text instructions as conditions may lead to an information bottleneck. The expressiveness of the instructions can be limited, and information loss may occur, as it is confined to the language modality.To bridge the gap between the language and vision modalities, we introduce N special [IMG] tokens in the vocabulary codebook of the MLLM. These special tokens have trainable word embeddings and should be predicted after the generated language instructions jointly during the reasoning phase. These appended visual tokens [IMG] are treated as latent imagination of subgoal image from the MLLM and we employ an output image projection module R to transform them into actual visual guidance U for diffusion model:
U = R({wlang + h[IMG]}, q)
The transformation over w can be seen as a general representation from language modality, while h represents a more grounded visual imagination that aligns with the language planning within the MLLM's reasoning. To simultaneously fine-tune the diffusion model and the MLLM, we employ the generation loss between the generated image and the groundtruth image.Enhancing Consistency between Vision and Language Planning
To further enhance the consistency between vision and language planning, we introduce an additional alignment objective between generated language instructions and visual images. Specifically, we feed both the generated image vt+1 and the current observation ot at planning step t into the MLLM and prompt it with understanding the differences between the two frames, which is exactly the action recognition captioning task in the perceive phase of PERIA. The response output Ẽt generated by the MLLM is compared with the groundtruth stepwise language instruction Et for consistency, and can be formulated as the alignment consistency loss:
C = {Et}t=0T, I = {(ot, vt+1)}t=0T,
Ẽt = MLLM(prompt, W(f={V(ot), V(vt+1)})),
LConsistency = ∑t=0T CELoss(Ẽt, Et)
Quantitative Results
Main Evaluation on Success Rate
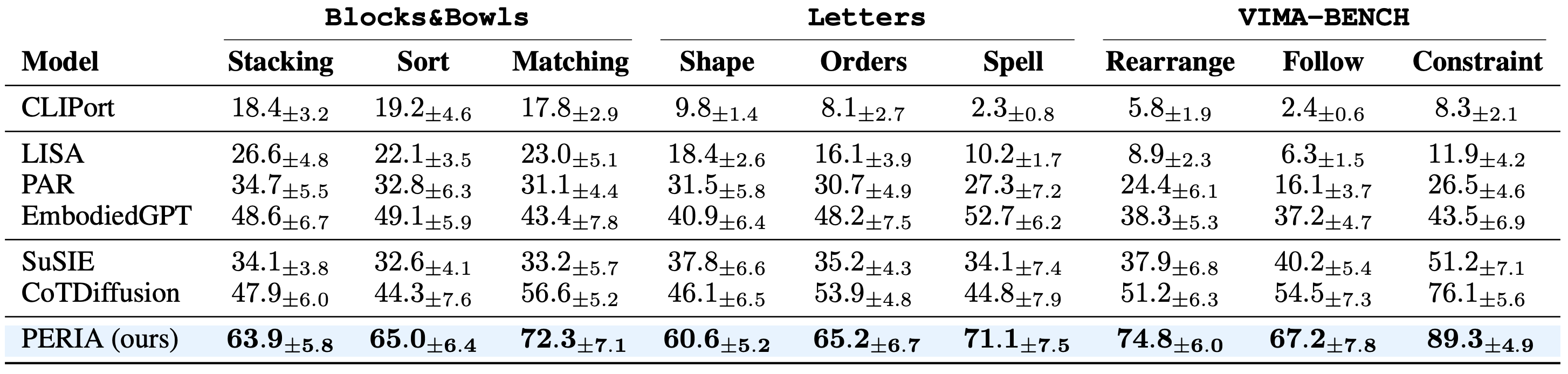
The baselines can be categorized into three types of planners: e2e planner, language planner, and visual planner. As expected, the end-to-end learning method performs the worst due to the lack of intermediate guidance, making it difficult for the policy to follow general instructions for long-horizon tasks. In contrast, the visual planner paradigm, which explicitly decomposes tasks into stepwise instructions and employs a hierarchical framework consisting of a language planner and a language-conditioned policy, shows more promise and demonstrates a clear advantage over the end-to-end approach. The visual planner paradigm, which generates intermediate keyframes, offers more intuitive guidance compared to language planning, and its advantage is more evident in VIMA-BENCH, where sub-tasks are challenging to describe sufficiently using language-only instructions. Our PERIA introduces an MLLM for explicit reasoning and generation, providing more sufficient and reliable intermediate guidance for instruction following in long-horizon tasks.
Accuracy of Language Planning
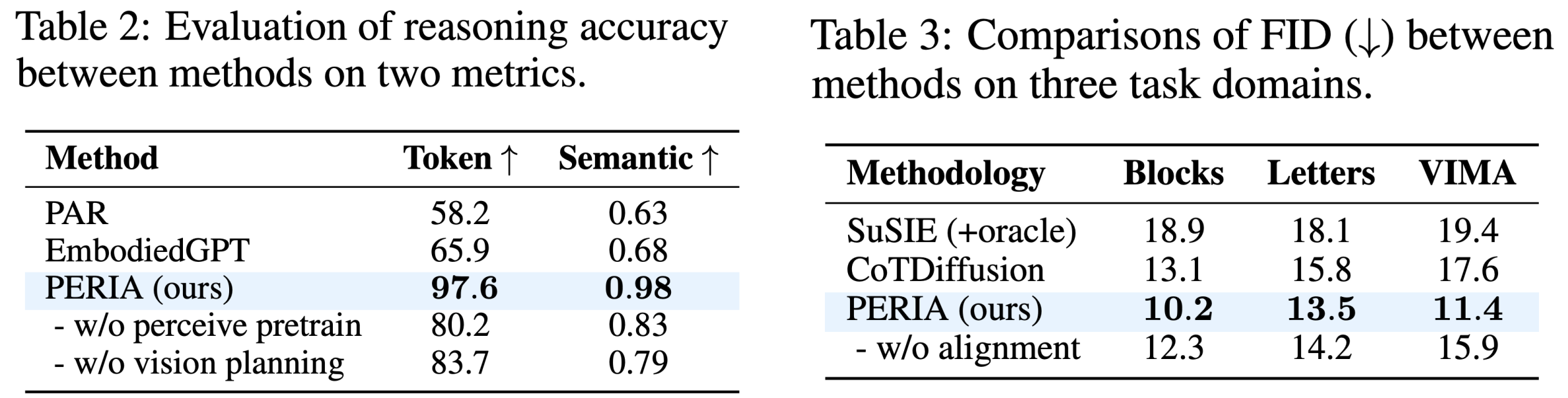
PERIA demonstrates the highest accuracy in both token-level and semantic-level comparisons.
Although PAR introduces LLMs for language planning, it relies on an isolated, out-of-the-shell VLM as a captioner to convert visual observations into language descriptions, which may cause details missing during hard captioning.
By jointly fine-tuning MLLM using the additional image generation loss, the supervision from visual aspects encourages promoting attention to visual details and spatial information for more grounded reasoning.
Fidelity of Vision Planning
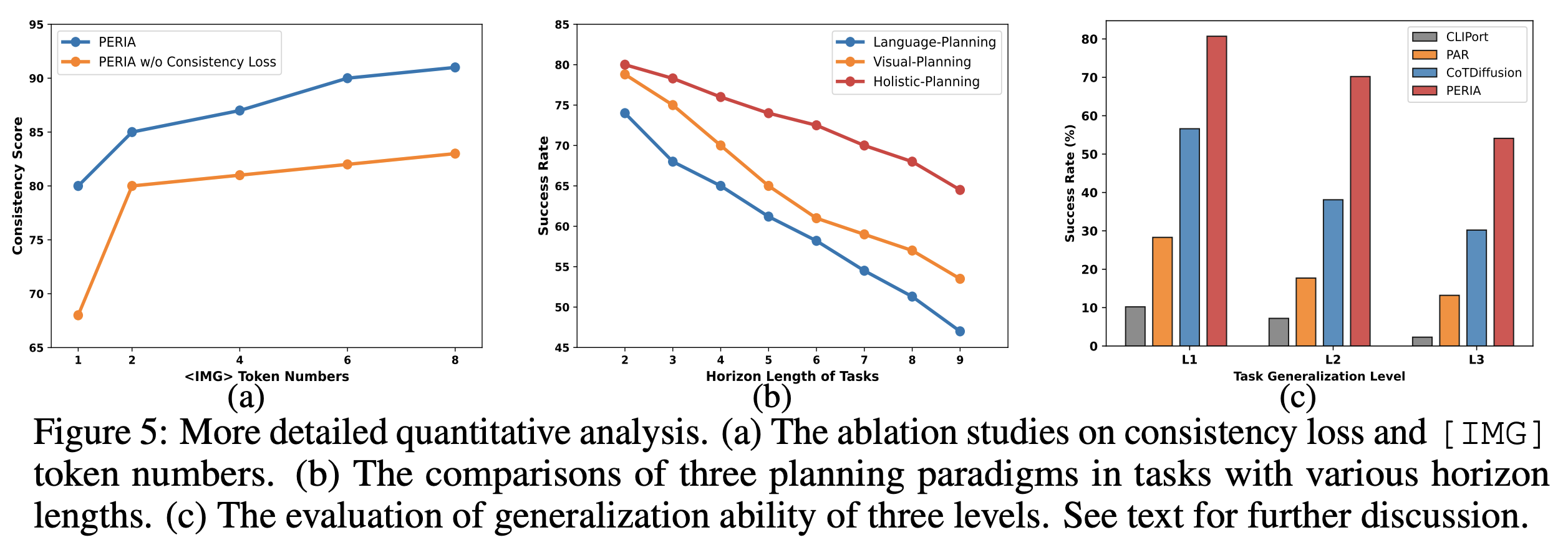
Consistency between Reasoning and Imagining
We leverage CLIP to measure the image-language similarity between generated instructions and images.
The additional consistency alignment loss explicitly constraints and encourages semantic alignment between the imagined images from vision planning and the reasoned stepwise instructions from language planning, significantly enhancing the collaboration and consistency between the two modalities. Furthermore, increasing the number of [IMG] tokens provides more expressive and sufficient guidance, facilitating the MLLM in producing semantically coherent language and image tokens.
However, the benefit of adding more tokens becomes marginal beyond a certain threshold.
Effectiveness of Holistic Planning
Generalization across Tasks
Examples of Tasks with General Complex Instructions
Blocks&Bowls
Move
Stack
Matching
Letters
Shape
Orders
Spell
Furthur Analysis
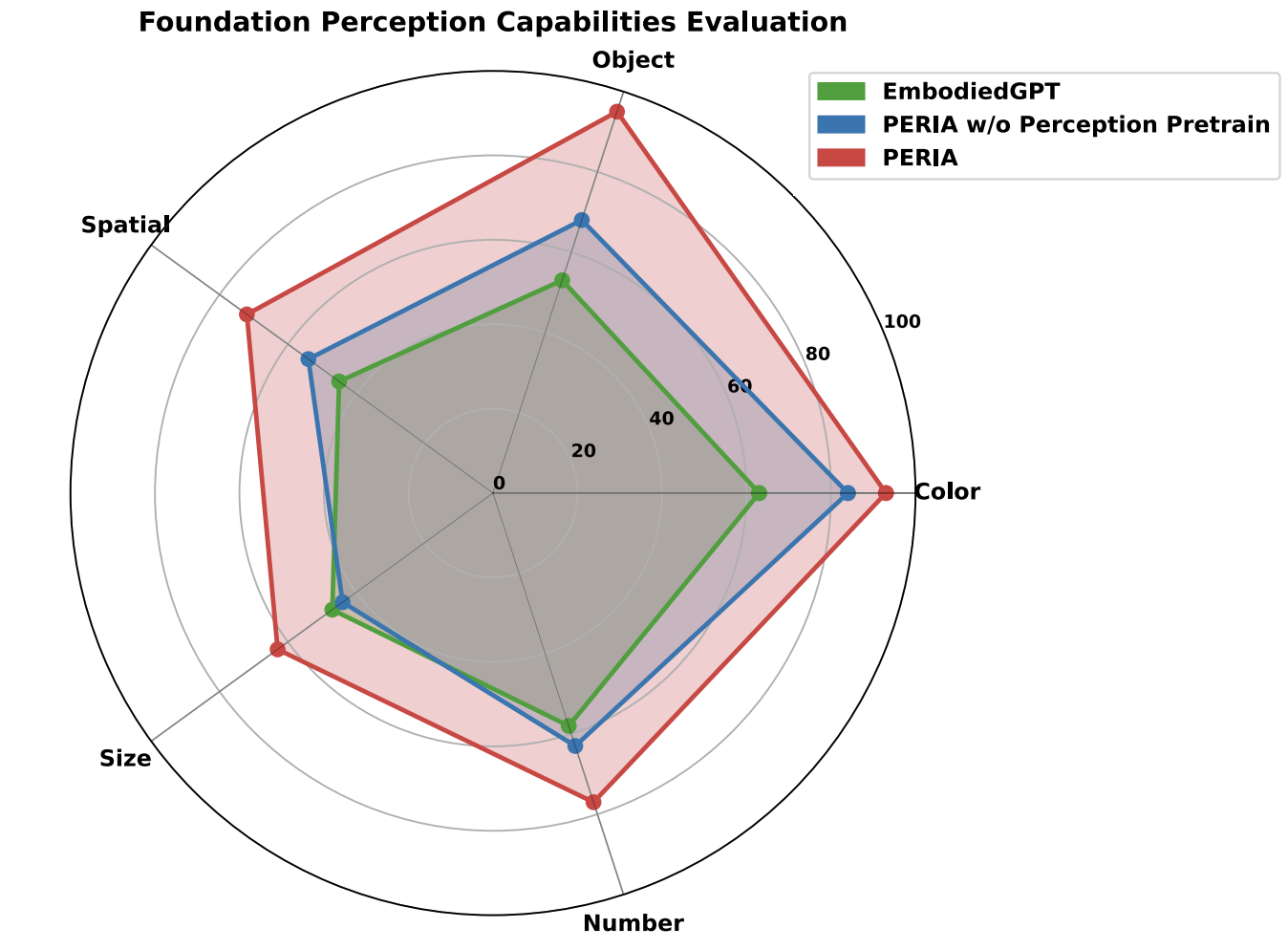
The Effect of Encoding-side Alignment
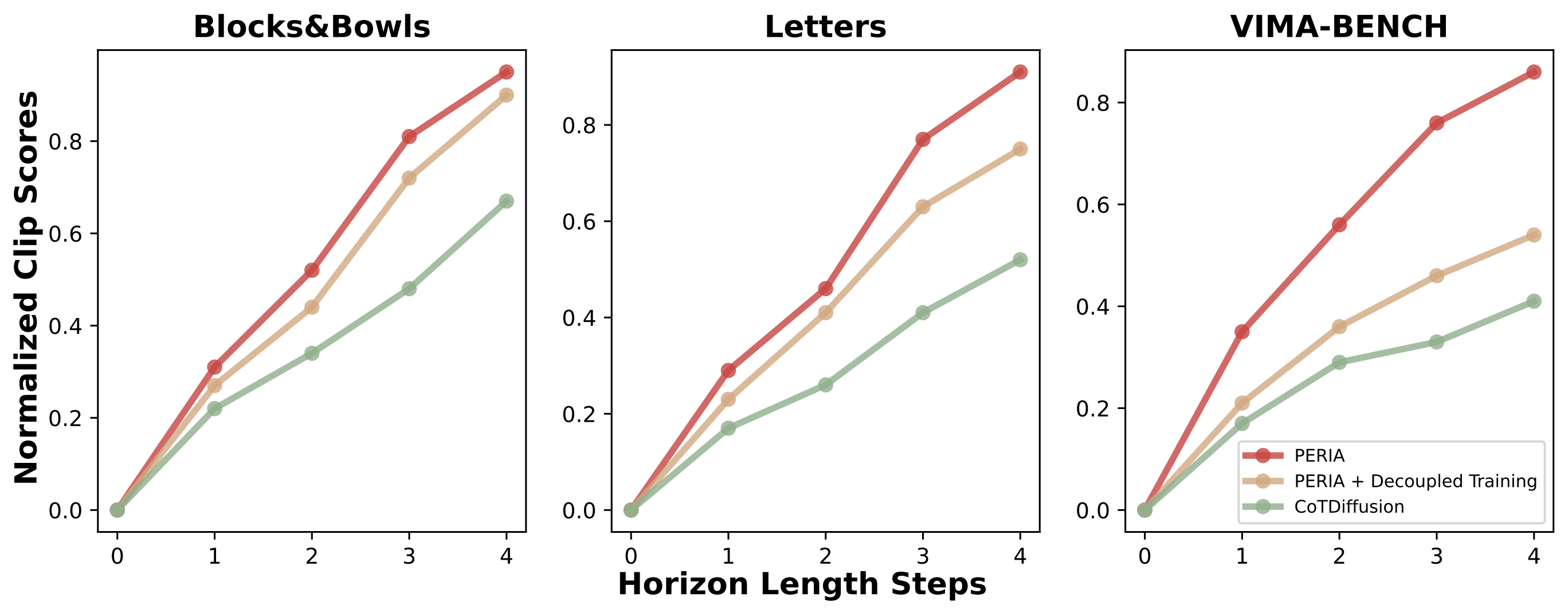
The Effect of Joint Training
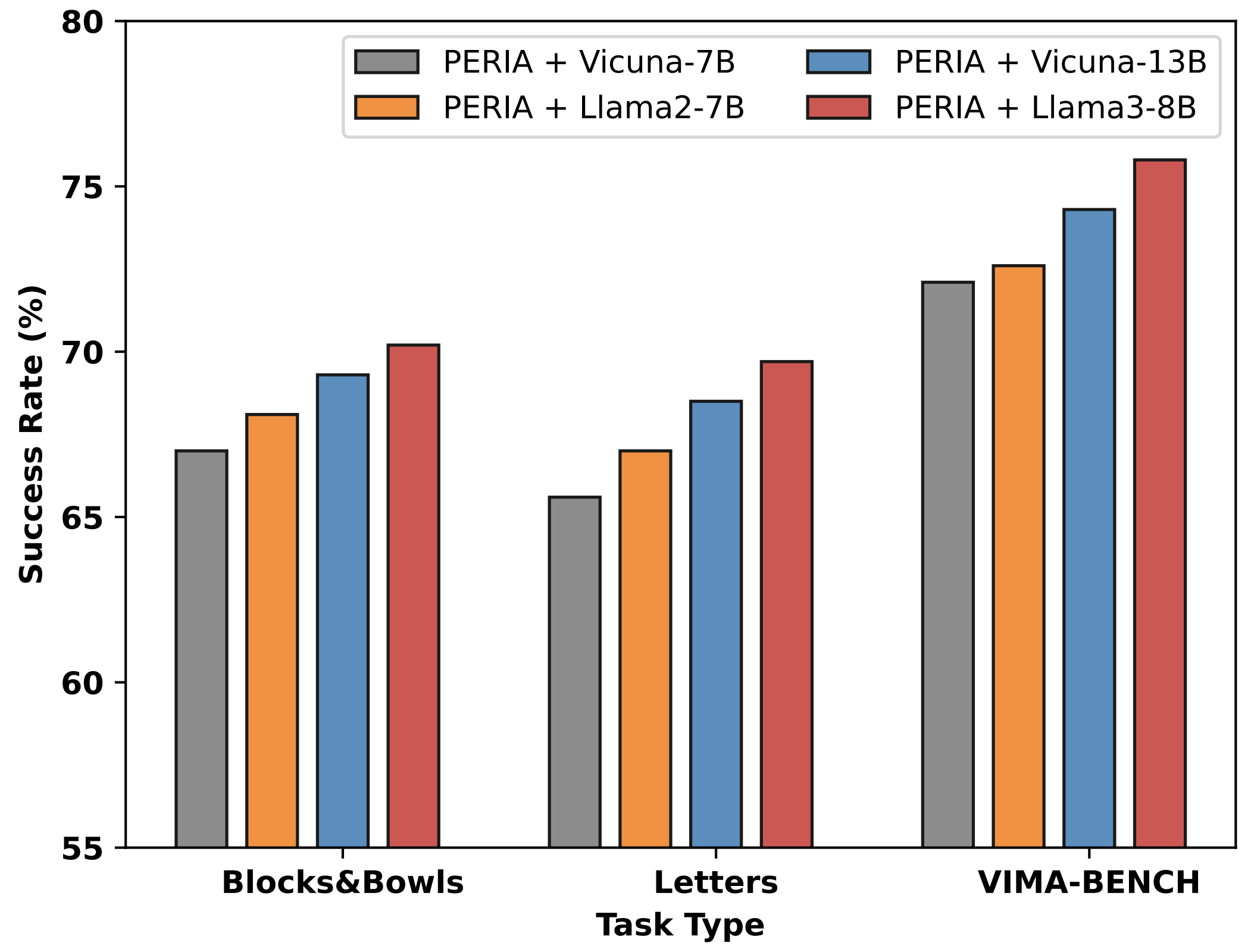
The Flexibility of LLM Backbones
Conclusion
We propose PERIA (Perceive, Eeason, Imagine, Act), a novel framework that integrates MLLM and diffusion-based image editing models to enable holistic language and vision planning for long-horizon manipulation tasks with complex instructions. We first perform a lightweight multi-modal alignment to enhance the MLLM's fundamental perception capabilities of visual details for manipulation, alleviating potential hallucinations. Then, we encourage MLLM to output rich latent visual tokens to guide diffusion model in generating images and explicitly align language instructions with visual subgoals to simultaneously unlock MLLM's reasoning and diffusion model's imagination capabilities. Extensive evaluations across three challenging benchmarks demonstrate that PERIA significantly outperforms competitive baselines in both instruction following accuracy and task success rate, while also enjoying better generalization ability across tasks. We believe PERIA highlights the potential of holistic language and vision planning and we hope this novel paradigm can provide some insights to robotics manipulation research of long-horizon tasks with complex instructions in free-form, towards more open embodied scenarios. One current bottleneck is the relatively high time cost of training and inference. Improving the joint training efficiency of MLLMs and diffusion models in a lightweight manner and accelerating image generation sampling are interesting directions for future work.